A (section) of a map of the data engineering space
11 minutes read | 2151 words by Ruben BerenguelThe map and problem described here were part of my presentation Mapping as a tool for thought, and mentioned in my interview with John Grant and Ben Mosior (to appear sometime soon in the Wardley Maps community youtube channel). I’m looking for ideas on how to make this map easier to understand and useful, so I posted it to the Wardley Maps Community forums requesting comments.
Problem I’m trying to solve
As a consultant (and as someone always trying to keep up with technology) I’m interested in being able to answer three questions of a language or technology:
- How easy it is to find work/workers in the area right now?
- How hard it is to learn?
- How easy is it going to be to find work/workers in the area once I’m proficient enough?
Also, I need to know the relationship between any of them.
This problem has been on the back of my mind for many years, and upon getting proficient with Wardley mapping, I thought I could just map it. Of course, it’s not a Wardley map, because the axes are completely different, but having anchors and movement, it is spiritually close enough for me.
In the diagram I will show in a while, I have placed technologies I am proficient in, currently learning, or looking forward to learn. In all of them I am at least a beginner in the sense that I know what they are used for and have done some minor PoC (proof of concept) to get an idea of how the work.
Looking for axis metrics
There are several ways you can address this technology space to answer the questions above. The first and easiest metric, and one of the axes I have used (Y axis) is Difficulty. Since I know something about each technology I can rank them on Difficulty, at least in relationship with each other. It’s only a qualitative metric of difficulty, because in any new technology there are always unknown unknowns. There is no movement assumed in this axis, because Difficulty is supposed to be consistent throughout (leaving aside the more you know the easier it is to learn as well as familiarity with similar concepts that offset that, you could think of these two concepts as doctrine in such a map).
One natural metric for the other axis could be popularity, as measured by any of the several programming language/framework popularity rankings. You can use popularity as one of the axes, and use arrows to indicate whether it is growing in popularity or diminishing in popularity. But, popularity alone does not help in answering questions 1 and 3. What we need is knowing how large the market for this technology is, and how large the pool of workers in this market is. Could we use either as an axis?
If we were to use market size as X axis, we would probably have large markets on the right and small markets on the left, we would likely use arrows to indicate growing markets and shrinking markets. But, market size alone won’t answer the questions either. A small thought experiment: imagine we have the largest market possible, it is growing… but the pool of workers for that technology is 2x the size of the market. It would be impossible to find work there (but, would be easy to find workers). This suggests that a possible correct for the X axis is market saturation, i.e. the ratio of market size with worker pool. Highly saturated markets are uninteresting to look for work, but are very interesting if you are starting a company: you’d have an easy time finding hires for that technology. Market saturation is related to flows (as in Systems thinking flow analysis) of users into a variable-sized container.
Markets become saturated in one of 3 ways:
- Market is growing, but the pool of workers grows faster
- Market is stagnating with a growing pool of workers
- Market is shrinking faster than the pool of workers is shrinking
Cases 1 and 2 are the most usual (I’d put Python as type 1 and Java as type 2), but 3 is an interesting situation: it would indicate a technology that has died in favour of another. Workers in that pool have retrained in the new technology, but are still in pool for the dying technology (for instance, traditional MapReduce).
Markets become desaturated in one of 3 ways as well:
- Market is growing faster than the pool of workers is growing
- Market is stagnating with a shrinking pool of workers
- Market is shrinking slower than the pool of workers is shrinking
Likewise, here, cases 1 and 3 may be the most interesting. I’d put Kubernetes in 1, and Scala in either 2 or 3. Please note that not only are these subjective evaluations, but are not meant to be negative. Scala has been my preferred language for a long while.
We can represent all these with slanted arrows: slant up covers growing markets, slant down covers shrinking markets. And then the arrow points left or right whether it is becoming saturated or desaturated.
With market saturation as an axis and arrows to indicate evolution of a technology, we can now almost answer questions 1 and 3. There is still the question of market size, which can’t be represented with such a relative measure. Although we could add circles to represent current market size, that would bring an already weird map to more weirdness. Hence, market size is not considered.
The map
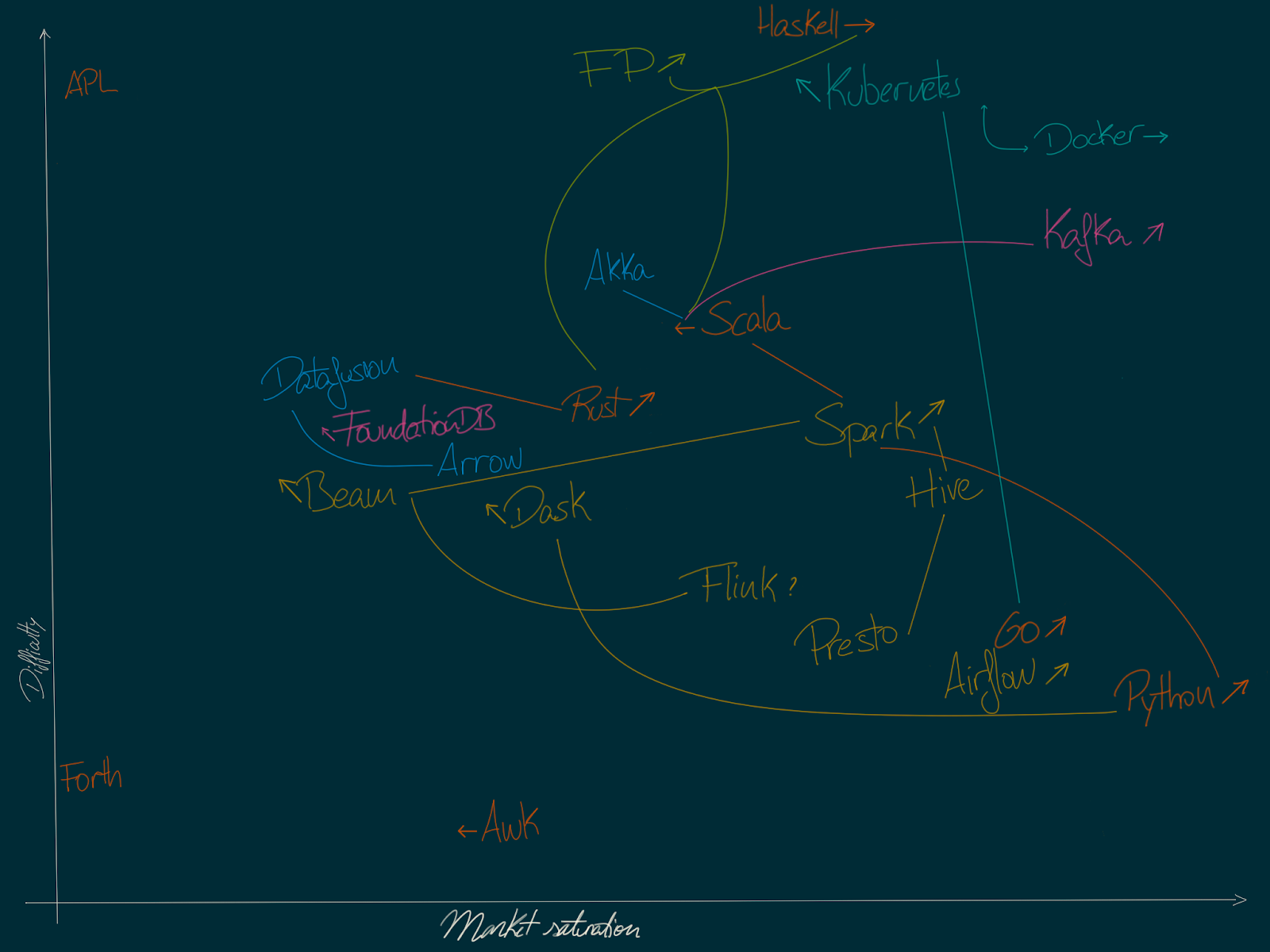
Tech landscape map
Here you can see the map. Before I get a bit into the topography of it, let me quickly define some of the technologies:
- APL: programming language based on non-ASCII symbols designed in the 70s. Not extensively used, but in use
- Airflow: workflow scheduler for data operations
- Akka: Scala/JVM actor framework used for reactive programming, clustering, stream processing, etc
- Arrow: cross-language platform for in-memory data. Used in Spark, Pandas, etc
- Awk: special-purpose programming language designed for text processing
- Beam: unified model for data processing pipelines. Can use Spark, Flink and others as execution engines
- Dask: cluster-capable, library for parallel computation in Python.
- Datafusion: rust-based, Arrow-powered in-memory data analytics
- Docker: containerisation solution
- FP: as in Functional Programming. Software development paradigm based on immutable state, among other things. Scala and Haskell are some the most mainstream languages for it
- Flink: cluster computing framework for big data, stream focused
- Forth: stack based, low level programming language. Not in common use.
- FoundationDB: multi-model distributed NoSQL database, offering “build your own abstraction” capabilities
- Go: statically typed, compiled programming language
- Haskell: statically typed, purely functional programming language
- Hive: data warehousing project over Hadoop, roughly based in “tables”
- Kafka: cluster based stream processing platform (often used as a message bus) written in Scala
- Kubernetes: container orchestration system for managing application deployment and scaling. Written in Go, depending (non-strictly) on Docker
- Presto: distributed SQL engine for big data
- Python: interpreted high level programming language, very extended in data science and engineering
- Rust: memory safe, concurrency safe programming language. Has some functional capabilities
- Scala: JVM based language offering strong typing and functional and OOP capabilities
- Spark: cluster computing framework for big data, batch and stream (stronger in batch)
These cover a range of the data engineering space (Flink, Spark), as well as technologies I want to get better at and are close enough (Kubernetes, FoundationDB) and technologies I know but are not directly related (AWK, APL, Forth) and are used as anchors.
Anchors
To display relative positions, I needed to anchor some of the technologies. For instance, Haskell and APL set the bar for difficulty, with AWK setting the minimum, and Python and Forth set the extremes for saturation. Everything else is placed in relation with these.
Links and colours
In the map, I have used colours to distinguish languages, frameworks, libraries, containerisation and databases. Colour is not fundamental though, links are. Related technologies are linked: Spark is written in Scala, and can be used with Scala, Python and other languages. Hence, changes in market saturation for Spark indirectly affect market saturation for Scala.
Empirical map division
We can think of the map as divided in 2 areas vertically (high barrier to entry and low barrier to entry) and 3 areas horizontally (saturated, accessible, desaturated).
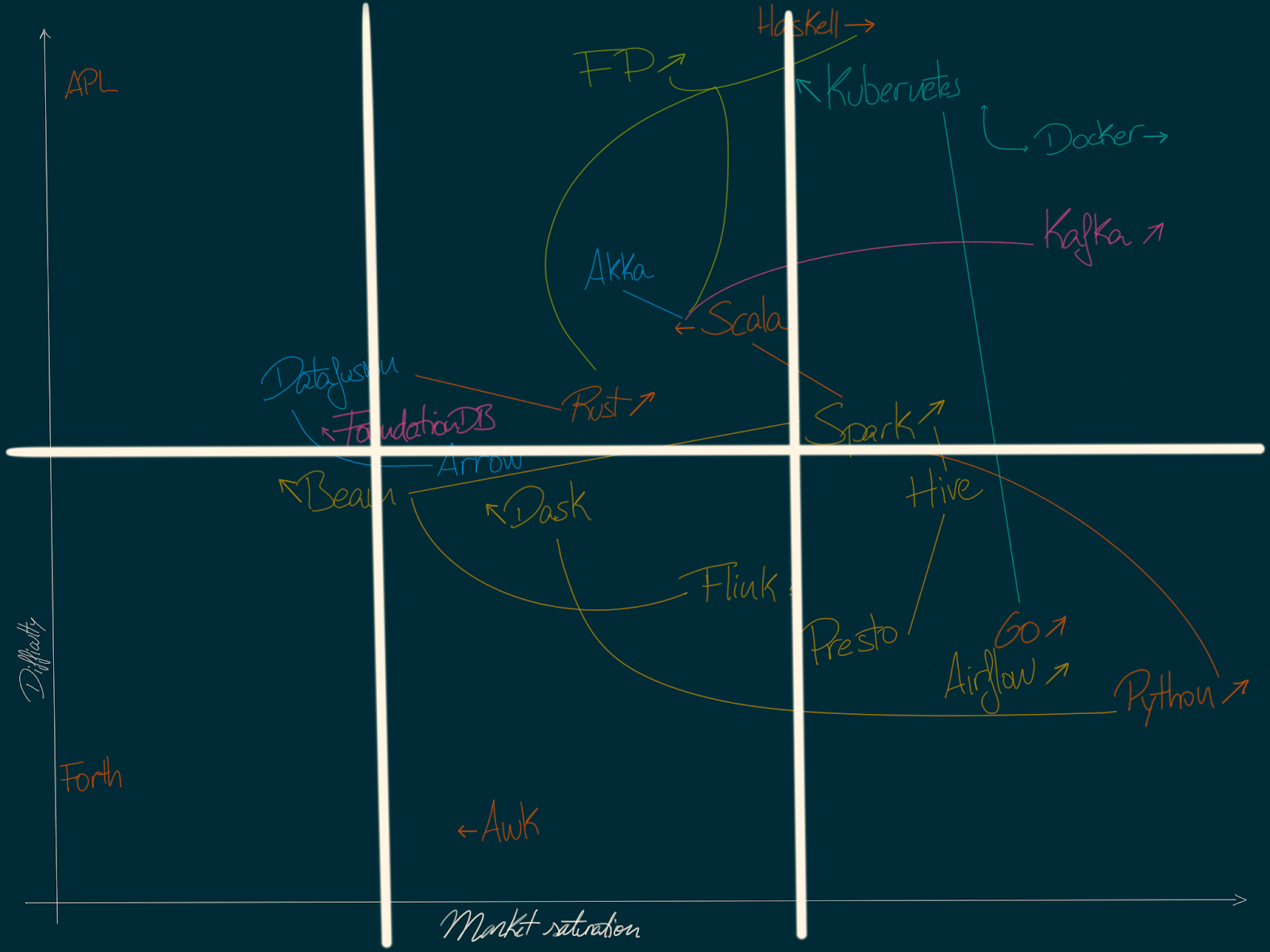
Tech landscape map with sectors
Quick overview
If you were a CTO, you’d probably be interested in:
- Low barrier to entry, saturated market for high turnover positions (easier and cheaper to hire and train)
- Accessible currently becoming saturated for more stable positions (becoming easier to hire in the future)
- High barrier to entry, with growing markets for proof of concepts, exploration (exploring new technologies that may make an impact in the future)
A map like the one above can help make these decisions.
For deciding on future work, I’d be (as a consultant) interested in:
- First, growing market, high barrier to entry for current learning. If the barrier to entry is too low and the market is lucrative enough any return on time investment will tend to 0 in the end otherwise.
- Second, accessible with low-to-mid barrier to entry for imminent work opportunities.
- Finally, to hedge bets on a long term plan, anything which is very low saturation, and where the market is unknown or may be in growth.
With this map (which is suited to my current knowledge and interests) I can definitely answer the question of where I should put my efforts right now.
Curiosities
Haskell and Rust raise interesting questions. Haskell has a very high barrier to entry, the market is not very large and might not be growing fast, but there are developers working in other languages (Scala, Rust, Kotlin, Go, even Python) that would love the opportunity to work in Haskell. This makes the Haskell job market actually saturated (or at least saturated if you consider worldwide market). Thus, starting a company focused on Haskell might not be as bad of an idea as it might sound. Similarly with Rust: Rust is growing as a side project language, the amount of developers familiar with the language is growing faster than the market and thus is an interesting target for a starting company.
We’d have Python on the other side: since it is taking over as the lingua franca of data science and engineering, and becoming one of the teaching languages at universities, the amount of developers with enough knowledge to become part of the work pool is growing faster than the market (even if the market for Python is growing at a fast pace). It makes it an ideal language for creating a company or a consultancy company (large pool of candidate workers), but not so interesting for being an independent consultant, since competition could be too large
Questions and further ideas
This is the approach and train of thought I have followed to trace these ideas, but it’s still a work in progress. I’d like to hear what you have to say about this: what would you change? What would you do different? I’m still unsure about using market saturation and arrows to show market and pool of workers behaviour, but I have not found anything easier to represent. Ideas? And here are some areas I’m unsure or where I have more questions.
What other approaches would you have taken to explore these questions?
There are probably many other ways you can take to approach these questions. What would be yours?
Do you think market size would need to be shown?
It could be shown with a circle (different sizes to be able to compare) below the arrow indicating behaviour of saturation but that could make the map way too complex. Any other ideas? Do you think it is that important, as long as saturation is taken into account?
Links between related technologies are a bit hazy
The links between technologies are a bit too abstract. An “increase” in “Python” moves “higher” Airflow, Spark, Dask and any related technologies… but in what sense? Popularity? Market share? Market saturation? I suspect the link is useful to see, and it is supposed to bring some dynamic/movement, but I’m still unsure how.
Flows
An interesting approach I didn’t pursue is using flow maps. For each programming language, there is a set of flows into other languages. For instance, developers in Scala have a tendency to be interested in Kotlin, Rust and Haskell, with some making the jump as soon as market is able to absorb them (and for each of these flows we can assume there is a non-zero flow to the other side). Similarly, we’d have flows from Python to Go and Scala, from Go to Rust. These could inform on market trends and behaviours, but they are not only hard to show on a map (what would be the axes? what would be the anchors?) but also might not be interesting enough on their own. What do you think?
- Apache Spark
- Data
- Wardley maps
- Python
- Scala
- Golang
- Big data
- Functional Programming
- Systems Thinking
- Essay