Haskset: Deckset presentations in reveal.js
7 minutes read | 1286 words by Ruben BerenguelAfter my happy experience with Haskell rewriting the ticketiser from Python to Haskell, I moved next on my list of rewrites.

A year or so ago I wrote a script in AWK that transformed a Markdown presentation formatted for Deckset into a Markdown presentation that Pandoc can convert into a reveal.js presentation, awkrdeck.
I wrote the script to be able to share my presentations with animated GIFs (which don’t show in the PDF export from Deckset). As such, it is very tied to how I format my presentations, and only offers features I use. With it I was able to export the initial versions of my PySpark talk.
The AWK code was not ready to handle variable footers and several features I had to use for my presentation at Spark+AI summit 2020. After writing a Markdown parser for bear-note-graph (using custom parser combinators), it was a no-brainer to rewrite this AWK mess into an extendable system.
I really love AWK. AWK is one of the best languages for quick-and-dirty exploration, even better than Python in some cases.
Of course, hticketiser (my previous Haskell project) made me re-think, so instead of reusing my Markdown parser in Python I decided to rewrite everything in Haskell from scratch. As before, it was an interesting problem, involving parsing and evaluation. A good excuse to learn to use parser combinators in Haskell.
I had already used parser combinators to parse user stories in the format “As a _, I want to _ so that _” in hticketiser, since I knew I was going to rewrite awkrdeck in Haskell. I have used the Parsec library. I’m curious to see how to use attoparsec, which is supposed to be faster. Parsec is fast enough for this code.
The problem to solve
Pandoc can convert presentations written in Markdown and using --- as slide separator into dynamic presentations that can be presented using reveal.js. Done quickly, they won’t look as good as the Deckset presentation: Deckset uses beautiful themes and custom configuration settings that can be embedded in Markdown.
The problem is reformatting the Markdown as written for Deckset into Markdown (possibly with HTML or CSS embedded) that Pandoc can convert into a nice reveal.js presentation. This also involves writing some CSS. That is kind of another problem I won’t address here, it was not fun.
The fundamental features I wanted to enable were:
- Split-images: If you add $N$ images in a slide, they will automatically split vertically. It works great for mixing concepts, or for the introductory slide

- Half-images: You can choose an image to have at the left or right, with text on the other. Makes slides more fluid, preventing too-much-text syndrome.

The AWK solution
The AWK version is at its core an (almost) one-pass parser-compiler, markdown-markdown. In other words, it reads the input line by line and emits new lines that already have the format adapted. It is partially split into a parsing and compiling step, since compiling needs lookback (or lookahead depending on how you see it): When you have $N$ images to use as a background, you need to know how many they are to choose the correct CSS classes for the split.
Internally, parsing generates an array of lines, that compiling rewrites into Markdown.
You can check the main parser/compiler here.
Problems with the AWK solution
There are no testing frameworks for AWK, and this is problem has complex testing issues: the final test is confirming, as a human that the generated presentation looks good.
Extending the parser/compiler is very hard. This is not because AWK is line noise, but because rolling a parser by hand with sparse documentation is problematic. Extending it is so much more.
The Haskell solution
The Haskell implementation is a more proper parser-compiler. It still needs improvement, but the parser is built using parser combinators, that emit Object instances. A Slide is formed by a list of Objects. An object can be a Markdown header, a text block, a list…
You can find the parser here and the “compiler” here.
Here’s one of the parsers for clarity:
headerParser :: Parsec.ParsecT String () Identity Object
headerParser = do
Parsec.spaces
header <- pack <$> Parsec.many1 (Parsec.char '#')
Parsec.char ' '
title <- pack <$> Parsec.manyTill Parsec.anyChar newLineTryParser
return (Header header title)
Change the import for import qualified Text.Parsec as P to avoid writing Parsec so many times. Or just import unqualified.
In the “compiler”, a function format takes an Object (and some formatting directives, needed for some cases) and emits Text with the correct formatting for Pandoc. As easy as that.
Here’s part of this function. Now that I have a clearer idea, I should rewrite this area, though.
format :: [Directive] -> Object -> T.Text
format _ (Header level text) =
T.concat [level <> "#",
" ",
reformatFootnote
(reformatInlinedEmph text)]
format _ Blank = "\n"
-- continues…
Here you can see already a couple of the “special stuff” that needs to be handled. Footnotes are not objects (due to how slides are created in the final formatting, they can’t be, at least not yet), thus need to be processed separately. Additionally, Markdown emphasis markers in headers are not (properly?) handled by Pandoc, thus need to be wrapped in spaces for them to be rendered. This is reformatInlinedEmph. Both this and footnotes are handled by parsers-rewriters, in one go.
This is what one of them looks like:
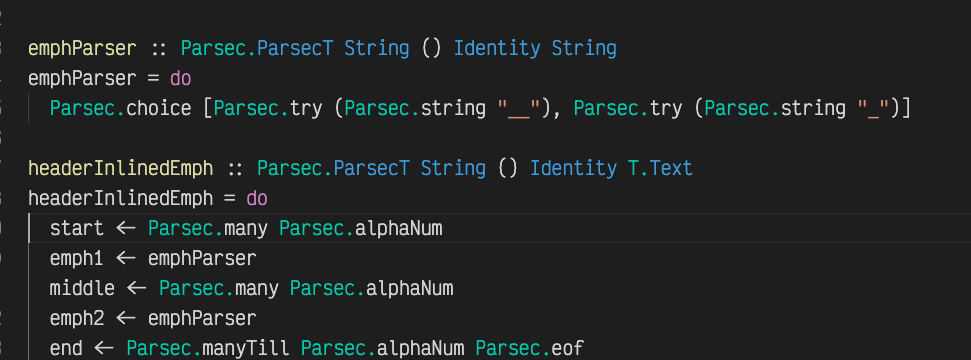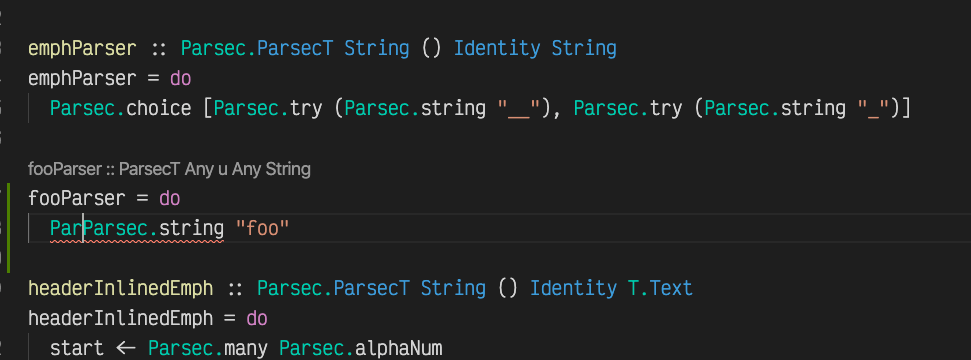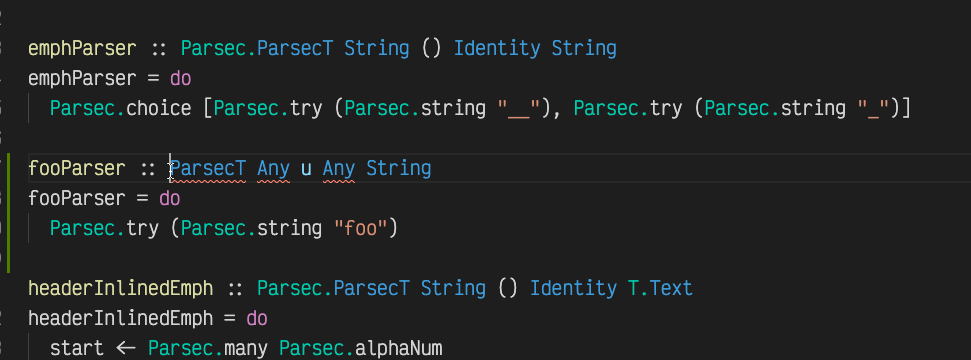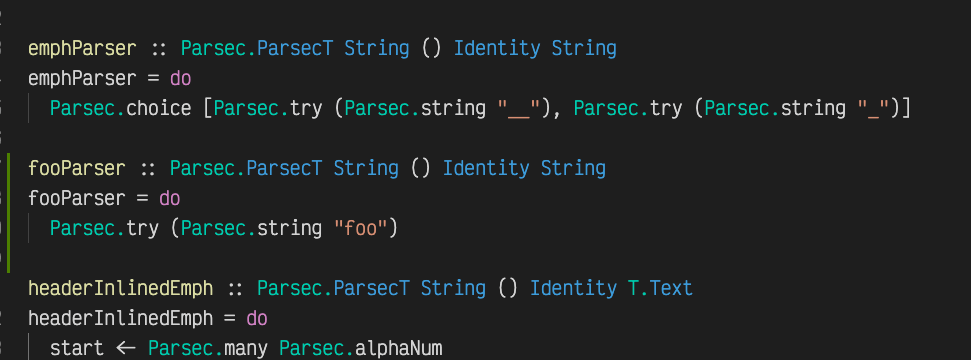
emphParser :: Parsec.ParsecT String () Identity String
emphParser = do
Parsec.choice [Parsec.try (Parsec.string "__"), Parsec.try (Parsec.string "_")]
headerInlinedEmph :: Parsec.ParsecT String () Identity T.Text
headerInlinedEmph = do
start <- Parsec.many Parsec.alphaNum
emph1 <- emphParser
middle <- Parsec.many Parsec.alphaNum
emph2 <- emphParser
end <- Parsec.manyTill Parsec.alphaNum Parsec.eof
return (pack (start ++ " " ++ emph1 ++ middle ++ emph2 ++ " " ++ end))
reformatInlinedEmph :: T.Text -> T.Text
reformatInlinedEmph text = T.intercalate " " (map rightParse (splitOn " " text))
where
rightParse text = case (Parsec.parse (Parsec.choice [Parsec.try headerInlinedEmph, Parsec.try anyUntilEof]) "" (unpack text)) of
Right thing -> thing
Left _ -> "[Failed parsing inlined formats]"
As you can see in the Left case at the bottom, I’m not throwing or emitting errors. I prefer outputting errors directly into the slide. The reason is simple: I’d rather have slides with some text errors I can fix by editing the HTML than having to rewrite parts of the code because the error stops the process. Imagine being in a hurry and needing the reveal.js version now.
Define newtype Parser = P.ParsecT String () Identity a or whatever makes me able to rewrite all those function headers, they are too verbose. Also use unwords or concat for that return pack.
Simon Peyton-Jones has said
Haskell is the finest imperative programming language.
Maybe half-jokingly, but the do block in headerInlinedEmph looks very clear, step-wise imperative. Readable.
Also, for a very typed, supposedly painful programming language, there is a surprisingly small amount of type annotations. Only the function headers. That doesn’t sound so bad, doesn’t it? Usually I don’t even type those, but just write the body of the function and the Haskell language server infers some options for them, you can choose any and they are automatically added:
Does it work?
Check for yourself:

Deckset original

Haskset+Pandoc+reveal.js
You can view the full reveal.js presentation for this talk in this repository (last link in the README). You can compare with the exported PDF.
Obviously I still need to tweak the CSS settings, and many other things (I have a pretty long todo listed in the README), but it already works 💪.
Next Haskell exploration will be about web frameworks and database connectors.