And e appears from nowhere!
5 minutes read | 1050 words by Ruben BerenguelAs I posted in Best Posts I Have Read in June and July, I liked a lot a numerical experiment in Re: Factor, a blog about learning the Factor programming language. The idea comes from another blog, this time about Clojure (a Lisp dialect running in the Java Virtual Machine), based on a footnote from Prime Obsession (Amazon affiliate link) by John Derbyshire. The footnote reads:
Here is an example of e turning up unexpectedly. Select a random number between 0 and 1. Now select another and add it to the first. Keep doing this, piling on random numbers. How many random numbers, on average, do you need to make the total greater than 1? The answer is e. (See sketch of proof below)
In the original post, a quick Clojure implementation is programmed, and in Re: Factor, a Factor implementation is added. When I originally read the post, I missed that the original version was in Clojure, and decided I was good to go by writing a Common Lisp version. I’d prefer a Forth version, but as Factor is close to Forth, it was close to cheating. Keep in mind that I wasn’t aware that the first version was in Clojure, though.
I switched to my emacs session and started slime. To my surprise, slime fired up Clojure, instead of Common Lisp! I didn’t remember that a few months back I got interested in this language, and set up slime to start Clojure. Oh well. My first program in Clojure, I thought.
The first function was easy to define. A function which picks random numbers from 0 to 1 and keeps on adding them until they are bigger than 1. As this was my first Clojure project, I didn’t want to bother learning how Clojure loops work… I wrote a recursive version. I did not try to make it even tail recursive:
(defn plus-random \[initial steps\]
; Initial and step start at 0. Will return how many times it takes
; to be greater than 1
(if (> initial 1)
steps
(plus-random (+ initial (rand)) (+ 1 steps))))
Ugly, I can hear you mutter. Maybe, but this was my first ever Clojure function, and it is almost the same I would write in Lisp. Moreover, after inspection, it looks like it is indeed tail recursive. It still amazes me that it worked. Of course, this can be improved, at least to make it more clear, with an auxiliary function:
(defn plus-random-aux [initial steps]
; Initial and step start at 0.
; Will return how many times
; it takes to be greater than 1
(if (\> initial 1)
steps
(recur (plus-random-aux (+ initial (rand)) (+ 1 steps)))))
(defn plus-random []
(plus-random-aux))
After this , we have to take averages of what the last function returns, for a large number of iterates. My first version of this function was recursive, too. But it blew away the stack, which is not good. I relented, and looked at Clojure’s loop construct, and the result was
(defn average-plus-random [iterates]
; Takes the average of "iterates" iterations of the previous
; function. Accumulator should start at 0
(loop \[n iterates accumulator 0\]
(if (= n 0)
(double (/ accumulator iterates))
(recur (dec n) (+ accumulator (PlusRandom))))))
Now, I look at recur, because it looks odd. Turns out, Clojure does no tail call optimization. Big fail for my plus-random function. Rewritten with a loop construct, with recur:
(defn PlusRandom []
(loop \[cnt 0 accumulator 0\]
(if (\> accumulator 1) cnt
(recur (+ 1 cnt) (+ accumulator (rand))))))
for a gain of an 11% execution time (from 3.9 to 3.5 seconds). It looks like too little for a tail call, but as most calls end either with 2 or 3 recursions, the improvement should be small? No! It turns out that the auxiliary function call adds an overhead, which accounts for a change from 3.9 seconds to 3.7 seconds. And the real improvement from tail call optimization is just a mere 6%.
Of course, if you want a quick program, you do it in C, if you want to program quick, you do in (insert your favourite quick language). The convergence of this scheme is too slow, too. But the answer comes from the mathematical proof.
user=> (time (AveragePlusRandom 100000)) “Elapsed time: 421.315711 msecs” 2.71938 user=> (time (AveragePlusRandom 1000000)) “Elapsed time: 3445.167485 msecs” 2.718408
user=> (time (AveragePlusRandom 10000000)) “Elapsed time: 34082.850845 msecs” 2.7182318
By the way, the proof from the convergence to e is quite straightforward, but this morning I was in no mood for this kind of problem (I am not fond of counting or probabilities) and googled it. I found it in the Google cache for Derbyshire’s book FAQ. I have edited a little his version
The first step is key. What’s the probability that the sum of just two random numbers exceeds 1? The same probability as that a point $(x,y)$ in the unit square (corners are at $(0,0)$, $(0,1)$, $(1,0)$, and $(1,1))$, satisfied the inequality $x + y \geq 1$. This is of course $\frac{1}{2}$; draw the diagonal from $(0,1)$ to $(1,0)$, and it’s the probability that $(x, y)$ is in the upper right triangle. If you now go to three random numbers, the chance that their sum exceeds 1 is got by “cutting a slice” across the unit cube through the corners $(1,0,0)$, $(0,1,0)$, and $(0,0,1)$. Observe that this pyramid (shown below) also cuts the unit square along the diagonal! This pyramid has volume $\frac{1}{6}$, and the probability $x + y + z \geq 1$ is then $1-\frac{1}{6}=\frac{5}{6}$.
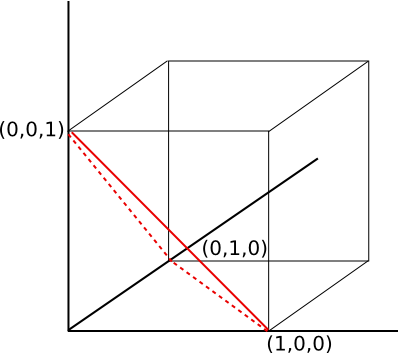
Photo by Romain Vignes on Unsplash
A little calculus, plus the principle of induction, shows that the pyramid (standard simplex) sliced off an $n$-dimensional unit cube by a hyper-plane through its corners $(1,0,0,0,…)$, $(0,1,0,0,…)$, $(0,0,1,0,…)$,…$ has volume $1/n!$ If you don’t believe it, you can check Wikipedia for the volume of the standard simplex.
The probability that a total of 1 is exceeded after adding $n$ random numbers is therefore $1 - \frac{1}{n!}$ The probability that a total of $1$ is exceeded after adding $n$ random numbers but not before is therefore $(1 - \frac{1}{n!}) - (1 - \frac{1}{\frac{n}{(n-1)!}}$, which simplifies to $\frac{n - 1}{n!}$. The expected number of selections until a total of 1 is exceeded is therefore the following sum:
$$\sum_{n=2}^\infty\frac{n-1}{n!}=\sum^\infty_{n=1}\frac{n}{n!}=e$$